

Author: Li Shen (Senior Vice President at PingCAP)
Database, operating system and compiler are known as the three big systems and regarded as the footstone of the whole computer software. Among them, database supports the businesses and is closer to the application layer. After decades of development, progress keeps emerging in this field.
Many people must have used databases of different kinds, but few have the experience of developing one, especially a distributed database. Knowing the principle and detail of implementing a database helps to advance one’s skill level, which is good for building other systems, and is also helpful to make better use of database.
I believe the best way to work on a technology is to dive deeply into an open source project of the field. Database is no exception. There are many good open source projects in the field of a standalone database. Among them, MySQL and PostgreSQL are the most famous and many people must have read their source code. However, in terms of distributed database, there are not many good open source projects and TiDB is one of the few. Many people, especially technophiles, hope to participate in this project. However, due to the complexity of distributed database, lots of people find it hard to understand the whole project. Therefore, I plan to write several articles to illustrate the technical principle of TiDB, including the technique that users can see as well as numerous invisible ones behind the SQL interface.
This is the first of our series of articles.
Storing data
I’d like to begin with the most fundamental function of a database — storing data.
There are lots of ways to store data and the easiest one is building a data structure in the memory to store data sent by users. For example, use an array to store data and add a new entry to the array when receiving a piece of data. This solution is simple, meets the basic needs and has good performance. But its drawback outweighs the advantages. The biggest problem is that as all data is stored in the memory, if the server stops or restarts, data would get lost.
To achieve data persistence, we can store data in the non-volatile storage medium, disk for example. We create a file on disk and append a new record to the file when receiving data. This is a durable storage solution.
But this is not enough. What if the disk is broken? To avoid the bad track of a disk, we can use RAID (Redundant Array of Independent Disks) for standalone redundant storage. However, what if the entire machine goes down? What if there is an outbreak of fire? RAID is no safe house.
Another solution is to store data in the network or use hardware or software for storage and replication. But the problem is how to guarantee the consistency between replicas. Securing the intactness and correctness of data is the basic requirement, the following problems are far more demanding:
- Does the database support disaster recovery of multi-datacenter?
- Is the write speed fast enough?
- Is it convenient to read data when data is stored?
- How to update the stored data? How does it deal with the concurrent revision?
- How to revise multiple records atomically?
All these problems are difficult to solve. But an excellent database storage system must be able to deal with each and every one of them.
For this, we have developed TiKV. Now, I want to share with you the design philosophy and basic concept of TiKV.
As we are talking about TiKV, I hope you can forget any concept about SQL and focus on how to implement TiKV, a huge distributed ordered Map that is of high performance and reliability.
Key-Value
A data storage system should, first and foremost, determine the store model of data. In other words, in which format should the data be stored. TiKV chooses the Key-Value model and offers a solution to traverse orderly. To put it simply: you can see TiKV as a huge Map where Key and Value are the original Byte array. In this Map, Key is arranged in a comparison order according to the raw binary bit of the byte array.
The following points need to be kept in mind:
- This is a huge Map of Key-Value pairs.
- In this Map, Key-Value pairs are ordered according to the Key’s binary sequence. We can Seek the position of a Key, and use the Next method to other Key-Value pairs, and these Key-Value pairs are all bigger than this one.
You might wonder the relation between the storage model that I’m talking about and the table in SQL. Here, I want to highlight: they are irrelevant.
RocksDB
Any durable storage engine stores data on disk and TiKV is no exception. But TiKV doesn’t write data to disk directly. Instead, it stores data in RocksDB and then RocksDB is responsible for the data storage. The reason is that it costs a lot to develop a standalone storage engine, especially a high-performance standalone engine. You need to do all kinds of detailed optimization. Fortunately, we found that RocksDB is an excellent open source standalone storage engine that meets all of our requirements. Besides, as the Facebook team keeps optimizing it, we can enjoy a powerful and advancing standalone engine without investing much effort. But of course we contribute a few lines of code to RocksDB and we hope that this project would get better. In a word, you can regard RocksDB as a standalone Key-Value Map.
Raft
Finding an effective, reliable and local storage solution is the important first step of this complex project. Now we are facing with a more difficult thing: how to secure the intactness and correctness of data when a single machine fails?
A good way is to replicate data to multiple machines. Then, when one machine crashes, we have replicas on other machines. But it is noted that the replicate solution should be reliable, effective and can deal with the situation of an invalid replica. It sounds difficult but Raft makes it possible.
Raft is a consensus algorithm and an equivalent to Paxos while Raft is easier to understand. Those who are interested in Raft can refer to this paper for more details. I want to point out that the Raft paper only presents a basic solution and the performance would be bad if strictly follow the paper. We have made numerous optimizations to implement Raft and for more detail, please refer to this blog written by our Chief Architect, Tang Liu.
Raft is a consensus algorithm and offers three important functions:
- Leader election
- Membership change
- Log replication
TiKV uses Raft to replicate data and each data change will be recorded as a Raft log. Through the log replication function of Raft, data is safely and reliably synchronized to multiple nodes of the Raft group.

In summary, through the standalone RocksDB, we can store data on a disk rapidly; through Raft, we can replicate data to multiple machines in case of machine failure. Data is written through the interface of Raft instead of to RocksDB. Thanks to the implementation of Raft, we have a distributed Key-Value and no longer need to worry about machine failure.
Region
In this section, I want to introduce a very important concept: Region. It is the foundation to comprehend a series of mechanism.
Before we begin, let’s forget about Raft and try to picture that all the data only has one replica.
As I mentioned earlier, TiKV is seen as a huge but ordered Key-Value Map. To implement the horizontal scalability of storage, we need to distribute data among multiple machines.
For a Key-Value system, there are two typical solutions to distribute data among multiple machines. One is to create Hash and select the corresponding storage node according to the Hash value; the other is to use Range and store a segment of serial Key in a storage node. TiKV chose the second solution and divided the whole Key-Value space into many segments. Each segment consists of a series of adjacent Key and we call such segment “Region”. There is a size limit for each Region to store data (the default value is 64MB and the size can be configured). Each Region can be described by a left-close-right-open interval, which is from StartKey to EndKey.
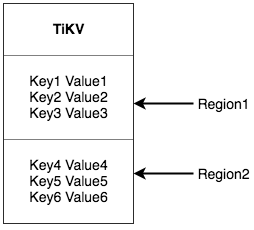
Please be reminded that the Region that I’m talking about has no relation with the Table in SQL! Please forget about SQL and focus on Key-Value for now.
After dividing data into Region, we’ll perform two more important tasks:
- Distributing data to all nodes in the cluster and use Region as the basic unit for data movement. And we also need to make sure that the number of Region in each node is roughly the same.
- Conducting Raft replication and membership management in Region.
These two tasks are very important and I’ll go through them one by one.
As for the first task, data is divided into many Regions according to the Key and all data in each Region is stored in one node. One component in our system is responsible to evenly distribute Regions to all nodes of the cluster. This, on the one hand, implements the horizontal scalability of the storage capacity (when a new node is added, the system will automatically schedule Regions on other nodes); on the other hand, load balancing is achieved (the situation that one node has many data but others have few will not happen). At the same time, to guarantee that the upper client can access to the data needed, another component will record the distribution of Regions among the nodes. In other words, you can query the exact Region of a Key and the node of that Region placed through any Key. I’ll share more information about these two components later.
Now let’s move to the second task. TiKV replicates data in Regions, which means data in one Region will have multiple replicas with the name “Replica”. Raft is used to achieve the data consistency among the Replicas. Multiple Replicas of one Region are saved in different nodes, which constitutes a Raft Group. One Replica serves as the Leader of the Group and the others as the Follower. All reads and writes are conducted through the Leader and then Leader replicates to Follower.
The following diagram shows the whole picture about Region and Raft group.

As we distribute and replicate data in Regions, we have a distributed Key-Value system that, to some extent, has the capability of disaster recovery. You no longer need to worry about the capacity or the problem of data loss caused by disk failure. This is cool but not perfect. We need more functions.
MVCC
Many databases implement multi-version concurrency control (MVCC) and TiKV is no exception. Assume that two clients update the Value of a Key at the same time, without MVCC, data would be locked. In a distributed scenario, this will lead to performance and deadlock problem.
TiKV implements MVCC by appending Version to Key. Without MVCC, TiKV’s data layout can be seen as:
~~ Key1 -> Value
~~ Key2 -> Value
~~ ......
~~ KeyN -> Value
With MVCC, the Key array in TiKV looks like this:
~~ Key1-Version3 -> Value
~~ Key1-Version2 -> Value
~~ Key1-Version1 -> Value
~~ ......
~~ Key2-Version4 -> Value
~~ Key2-Version3 -> Value
~~ Key2-Version2 -> Value
~~ Key2-Version1 -> Value
~~ ......
~~ KeyN-Version2 -> Value
~~ KeyN-Version1 -> Value
~~ ......
It is noted that as for multiple versions of a Key, we put the bigger number first (you can review the Key-Value section in which I mentioned that Key is an ordered array). In this way, when a user gets the Value by Key + <Version>, he can construct the Key of MVCC with Key and Version, which is Key-<Version>. Then he can directly Seek(Key-Version) and locate the first position that is greater than or equal to this Key-Version. For more detail, see MVCC in TiKV.
Transaction
Transaction of TiKV adopts the Percolator model and has lots of optimizations. I don’t want to dive deep since you can read the paper and our articles(Currently in Chinese). What I want to say is that transaction in TiKV uses the optimistic lock. During the execution process, it will not detect write conflict. Only in the commit phase will it detect conflicts. The transaction that finishes committing earlier will be written successfully while the other would retry. If the write conflict of the business is not serious, the performance of this model is very good. For example, it works well to randomly update some rows of data in a large table. However, if the write conflict is severe, the performance would be bad. Take counter as an extreme example. The situation that many clients update a few rows at the same time leads to serious conflicts and numerous invalid retry.
Miscellaneous
Up to now, I have introduced the basic concept and some details of TiKV, the layered structure of this distributed and transactional Key-Value engine and how to implement multi-datacenter disaster recovery. I’ll introduce how to construct the SQL layer on top of the storage model of Key-Value in the next article.
Keep reading:
Announcing TiDB 6.2 with Better Observability, Faster Execution, Enhanced Disaster Recovery, and More
TiDB Internal (III) – Scheduling
TiDB Internal (II) – Computing



TiDB Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Serverless
A fully-managed cloud DBaaS for auto-scaling workloads