
Authors:
Editors: Calvin Weng, Tom Dewan
Chaos Mesh is an open-source chaos engineering platform for Kubernetes. Although it provides rich capabilities to simulate abnormal system conditions, it still only solves a fraction of the Chaos Engineering puzzle. Besides fault injection, a full chaos engineering application consists of hypothesizing around defined steady states, running experiments in production, validating the system via test cases, and automating the testing.
This article describes how we use TiPocket, an automated testing framework to build a full Chaos Engineering testing loop for TiDB, our distributed database.
Why do we need TiPocket?
Before we can put a distributed system like TiDB into production, we have to ensure that it is robust enough for day-to-day use. For this reason, several years ago we introduced Chaos Engineering into our testing framework. In our testing framework, we:
- Observe the normal metrics and develop our testing hypothesis.
- Inject a list of failures into TiDB.
- Run various test cases to verify TiDB in fault scenarios.
- Monitor and collect test results for analysis and diagnosis.
This sounds like a solid process, and we’ve used it for years. However, as TiDB evolves, the testing scale multiplies. We have multiple fault scenarios, against which dozens of test cases run in the Kubernetes testing cluster. Even with Chaos Mesh helping to inject failures, the remaining work can still be demanding—not to mention the challenge of automating the pipeline to make the testing scalable and efficient.
This is why we built TiPocket, a fully-automated testing framework based on Kubernetes and Chaos Mesh. Currently, we mainly use it to test TiDB clusters. However, because of TiPocket’s Kubernetes-friendly design and extensible interface, you can use Kubernetes’ create and delete logic to easily support other applications.
How does it work
Based on the above requirements, we need an automatic workflow that:
Injecting chaos – Chaos Mesh
Fault injection is the core chaos testing. In a distributed database, faults can happen anytime, anywhere—from node crashes, network partitions, and file system failures, to kernel panics. This is where Chaos Mesh comes in.
Currently, TiPocket supports the following types of fault injection:
- Network: Simulates network partitions, random packet loss, disorder, duplication, or delay of links.
- Time skew: Simulates clock skew of the container to be tested.
- Kill: Kills the specified pod, either randomly in a cluster or within a component (TiDB, TiKV, or Placement Driver (PD)).
- I/O: Injects I/O delays in TiDB’s storage engine, TiKV, to identify I/O related issues.
With fault injection handled, we need to think about verification. How do we make sure TiDB can survive these faults?
Verifying chaos impacts: test cases
To validate how TiDB withstands chaos, we implemented dozens of test cases in TiPocket, combined with a variety of inspection tools. To give you an overview of how TiPocket verifies TiDB in the event of failures, consider the following test cases. These cases focus on SQL execution, transaction consistency, and transaction isolation.
Fuzz testing: SQLsmith
SQLsmith is a tool that generates random SQL queries. TiPocket creates a TiDB cluster and a MySQL instance. The random SQL generated by SQLsmith is executed on TiDB and MySQL, and various faults are injected into the TiDB cluster to test. In the end, execution results are compared. If we detect inconsistencies, there are potential issues with our system.
Transaction consistency testing: Bank and Porcupine
Bank is a classical test case that simulates the transfer process in a banking system. Under snapshot isolation, all transfers must ensure that the total amount of all accounts must be consistent at every moment, even in the face of system failures. If there are inconsistencies in the total amount, there are potential issues with our system.
Porcupine is a linearizability checker in Go built to test the correctness of distributed systems. It takes a sequential specification as executable Go code, along with a concurrent history, and it determines whether the history is linearizable with respect to the sequential specification. In TiPocket, we use the Porcupine checker in multiple test cases to check whether TiDB meets the linearizability constraint.
Transaction Isolation testing: Elle
Elle is an inspection tool that verifies a database’s transaction isolation level. TiPocket integrates go-elle, the Go implementation of the Elle inspection tool, to verify TiDB’s isolation level.
These are just a few of the test cases TiPocket uses to verify TiDB’s accuracy and stability. For more test cases and verification methods, see our source code.
Automating the chaos pipeline – Argo
Now that we have Chaos Mesh to inject faults, a TiDB cluster to test, and ways to validate TiDB, how can we automate the chaos testing pipeline? Two options come to mind: we could implement the scheduling functionality in TiPocket, or hand over the job to existing open-source tools. To make TiPocket more dedicated to the testing part of our workflow, we chose the open-source tools approach. This, plus our all-in-K8s design, lead us directly to Argo.
Argo is a workflow engine designed for Kubernetes. It has been an open-source product for a long time, and has received widespread attention and application.
Argo has abstracted several custom resource definitions (CRDs) for workflows. The most important ones include Workflow Template, Workflow, and Cron Workflow. Here is how Argo fits in TiPocket:
- Workflow Template is a template defined in advance for each test task. Parameters can be passed in when the test is running.
- Workflow schedules multiple workflow templates in different orders, which form the tasks to be executed. Argo also lets you add conditions, loops, and directed acyclic graphs (DAGs) in the pipeline.
- Cron Workflow lets you schedule a workflow like a cron job. It is perfectly suitable for scenarios where you want to run test tasks for a long time.
The sample workflow for our predefined bank test is shown below:
spec:
entrypoint: call-tipocket-bank
arguments:
parameters:
- name: ns
value: tipocket-bank
- name: nemesis
value: random_kill,kill_pd_leader_5min,partition_one,subcritical_skews,big_skews,shuffle-leader-scheduler,shuffle-region-scheduler,random-merge-scheduler
templates:
- name: call-tipocket-bank
steps:
- - name: call-wait-cluster
templateRef:
name: wait-cluster
template: wait-cluster
- - name: call-tipocket-bank
templateRef:
name: tipocket-bank
template: tipocket-bank
In this example, we use the workflow template and nemesis parameters to define the specific failure to inject. You can reuse the template to define multiple workflows that suit different test cases. This allows you to add more customized failure injections in the flow.
Besides TiPocket’s sample workflows and templates, the design also allows you to add your own failure injection flows. Handling complicated logics using codable workflows makes Argo developer-friendly and an ideal choice for our scenarios.
Now, our chaos experiment is running automatically. But if our results do not meet our expectations? How do we locate the problem? TiDB saves a variety of monitoring information, which makes log collecting essential for enabling observability in TiPocket.
Visualizing the results: Loki
In cloud-native systems, observability is very important. Generally speaking, you can achieve observability through metrics, logging, and tracing. TiPocket’s main test cases evaluate TiDB clusters, so metrics and logs are our default sources for locating issues.
On Kubernetes, Prometheus is the de-facto standard for metrics. However, there is no common way for log collection. Solutions such as Elasticsearch, Fluent Bit, and Kibana perform well, but they may cause system resource contention and high maintenance costs. We decided to use Loki, the Prometheus-like log aggregation system from Grafana.
Prometheus processes TiDB’s monitoring information. Prometheus and Loki have a similar labeling system, so we can easily combine Prometheus’ monitoring indicators with the corresponding pod logs and use a similar query language. Grafana also supports the Loki dashboard, which means we can use Grafana to display monitoring indicators and logs at the same time. Grafana is the built-in monitoring component in TiDB, which Loki can reuse.
Putting them all together – TiPocket
Now, everything is ready. Here is a simplified diagram of TiPocket:
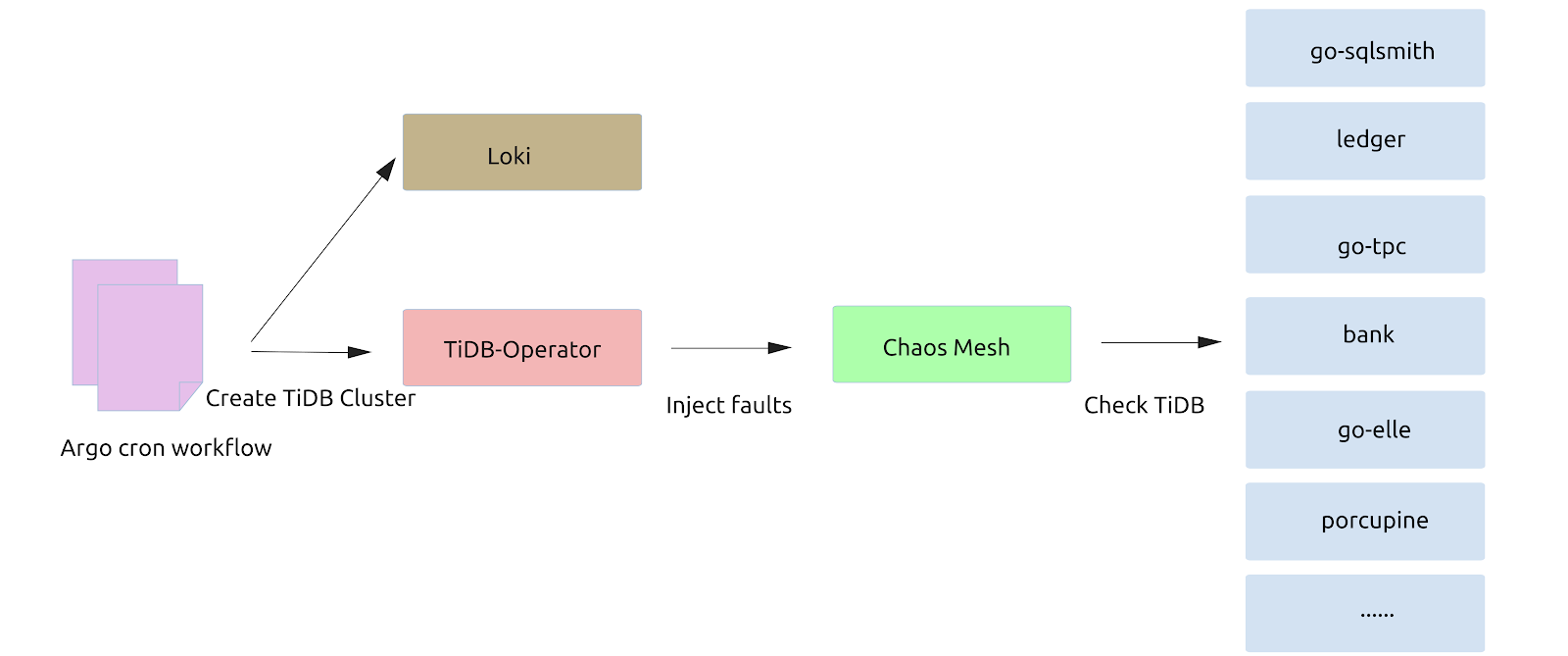
TiPocket architecture
As you can see, the Argo workflow manages all chaos experiments and test cases. Generally, a complete test cycle involves the following steps:
- Argo creates a Cron Workflow, which defines the cluster to be tested, the faults to inject, the test case, and the duration of the task. If necessary, the Cron Workflow also lets you view case logs in real-time.

Argo workflow
- At a specified time, a separate TiPocket thread is started in the workflow, and the Cron Workflow is triggered. TiPocket sends TiDB Operator the definition of the cluster to test. In turn, TiDB Operator creates a target TiDB cluster. Meanwhile, Loki collects the related logs.
- Chaos Mesh injects faults in the cluster.
- Using the test cases mentioned above, the user validates the health of the system. Any test case failure leads to workflow failure in Argo, which triggers Alertmanager to send the result to the specified Slack channel. If the test cases complete normally, the cluster is cleared, and Argo stands by until the next test.

Alert in Slack
This is the complete TiPocket workflow.
Join us
Chaos Mesh and TiPocket are both in active iterations. We have donated Chaos Mesh donated to CNCF, and we look forward to more community members joining us in building a complete Chaos Engineering ecosystem. If this sounds interesting to you, check out our website, or join #chaos-mesh in Slack.



TiDB Dedicated
A fully-managed cloud DBaaS for predictable workloads
TiDB Serverless
A fully-managed cloud DBaaS for auto-scaling workloads